
ChatGPT-4 Versus Decision Analyst’s Deep Learning Model
By John V. Colias, Ph.D.
-
With all the hype and hoopla over generative AI, we decided to do some experimental work to see how well ChatGPT-4 performed versus Decision Analyst’s Deep Learning Model, a multi-layer neural network classification model.
The unique aspect of generative AI systems, such as ChatGPT, Google Gemini, and many others, is the ability for users to interact with the generative AI in a dialogue of “prompt” and “response.” This investigation only explored textual prompts and responses, not audio, video, or images.

ChatGPT evolved out of deep learning methods that appeared in the early 2010’s. Since then, deep learning models have achieved prominence in image classification, speech recognition, improved search results on the web, and more recently, the ability to understand text questions and to answer in natural language (“prompt” and the “response”).
Our investigation addresses the important question of how should generative AI models like ChatGPT be used in the marketing research industry? More specifically, how well do ChatGPT responses align with human-produced responses? Is additional modeling needed to further align ChatGPT and human-produced responses?
In survey-based research, open-ended questions are frequently included, and the responses to these open-ended questions are typically coded by hand. That is, a real-live person (an analyst) reads each of the answers to open-ended questions and assigns a numeric code (sometimes called a label) to each unique idea in the text answer. This process is also called Content Analysis, a widely used analytical method favored by intelligence agencies around the world to mine a deeper understanding of content published by competitive countries. Survey open-ended questions are used in marketing research, social research, and political research, and all the answers must be coded (or labeled) by a thinking, intelligent human being.
Human coding of open-ended responses is labor intensive and very expensive, so we decided to see if ChatGPT-4 could accurately assign codes (or labels) to the answers to open-ended questions. As a point of comparison, we used a Decision Analyst Deep Learning Model to code the same dataset.
We asked Nuance (Decision Analyst's coding and text analytics subsidiary) to assign human codes (or labels) to 2,000 answers for the open-ended question: “In your opinion, what are the major economic problems in your country? Please give as much detail as possible.” The data included responses from the US, Canada, India, UK, Australia, New Zealand, and the Netherlands. The responses were all provided in English.
Then, we supplied ChatGPT-4 with the text of the human-produced codes (the prompt) and asked it to assign codes or labels to the same 2,000 answers. Next, we trained our Deep Learning Model on a random sample of 500 human-coded answers, and then randomly selected 1,000 human-coded answers from the 2,000 dataset (excluding the 500 records chosen as the training dataset). Our Deep Learning Model then coded the answers in these same 1,000 records. ChatGPT-4 and Decision Analyst’s Deep Learning Model yielded the following results for the same 1,000 answers. The percentages in the following chart assume that the human-coded results are the “Gold Standard” (that is, 100% correct).
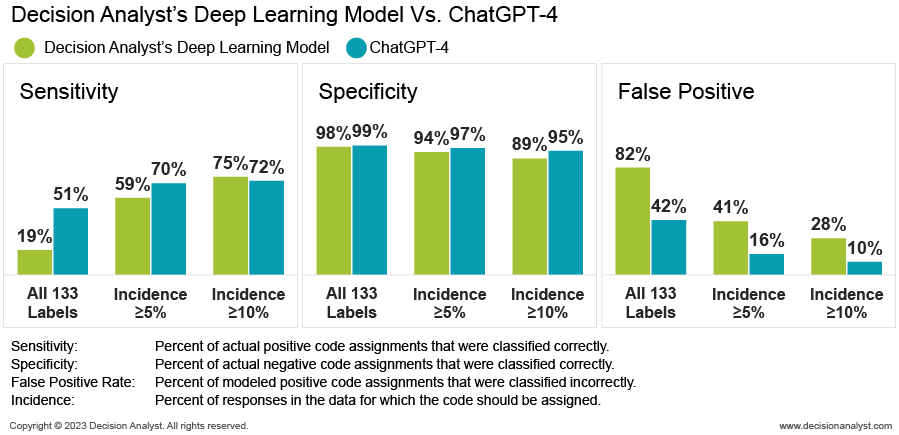
Clearly, ChatGPT-4 performed better than Decision Analyst’s Deep Learning Model. However, the gap in performance declined for codes or labels with higher incidence. For codes with at least 10% incidence, the sensitivity gap shifted from a significant "win" for ChatGPT-4 (51% versus 19%) to Decision Analyst's Deep Learning Model outperforming ChatGPT-4 by 3 percentage points (75% versus 72%).
It was expected that ChatGPT-4 would outperform Decision Analyst’s Deep Learning Model, since the former was developed using a massive number of texts to train it to understand the text responses and the meaning of the codes or labels. Indeed, the ChatGPT-4 embedding vectors, the numeric representation of the meaning of the text, provided most of the advantage. To demonstrate this point, we trained another Decision Analyst deep learning model to use ChatGPT-3.5 embedding vectors as predictors. This second deep learning model performed admirably and significantly outperformed ChatGPT-4 in sensitivity for higher-incidence codes.

- None of the AI and deep learning systems are perfectly accurate. Neither system produces results that perfectly align with human-produced results.
- A key benefit of using ChatGPT-4 is that no modeling is required—there was only a prompt that included (a) the text of the primary and secondary categories (i.e., the code nets and the codes), (b) the text of the question response, and (c) a request to assign appropriate primary and secondary categories to the response.
- Evidence suggests that ChatGPT-4 prompt-response output can benefit from additional modeling to further align results with human-produced results.
- For ChatGPT-4, sample size (the total number of survey respondents who answered the question) did not matter since no additional modeling was done. That is, ChatGPT-4 uses a massive model with billions of parameters, so no additional modeling using survey data is needed.
- Interestingly, ChatGPT-4 performance also improved with higher incidence. This would be an area for further investigation.
We should point out that human-produced code assignments (given a code book also human produced) were assumed to be “truth.” One might suggest that humans could be subject to error and bias. On the other hand, one might suspect the same flaws in ChatGPT-3.5 and ChatGPT-4.
About the Author
John Colias, Ph.D. (jcolias@decisionanalyst.com) is a Senior VP Research & Development at Decision Analyst. He may be reached at 1-800-262-5974 or 1-817-640-6166.
Copyright © 2024 by Decision Analyst, Inc.
This posting may not be copied, published, or used in any way without written permission of Decision Analyst.
